Разреженная таблица и LCA
В этой лекции мы решим две классические задачи:
- Static RMQ (англ. range minimum query) — отвечать на запросы минимума на отрезке массива, который не меняется со временем.
- LCA (англ. least common ancestor) — для двух вершин корневого дерева находить их наименьшего общего предка.
Сначала разберём разреженную таблицу — структуру данных, отвечающую на static RMQ за \(O(1)\) с препроцессингом за \(O(n \log n)\). После этого покажем, как сводится одна задача к другой, и тем самым научимся отвечать на LCA-запросы тоже за \(O(1)\).
Разреженная таблица
Разреженная таблица (англ. sparse table) — структура данных для статической задачи RMQ. Препроцессинг занимает \(O(n \log n)\) времени и памяти, каждый запрос — \(O(1)\).
Определение
Заведём двумерный массив mn размера \(\lceil \log_2 n \rceil \times n\):
\[ \text{mn}[k][i] = \min(a_i, a_{i+1}, \ldots, a_{i + 2^k - 1}) \]
Иначе говоря, mn[k][i] хранит минимум на отрезке длины \(2^k\), начинающемся с позиции \(i\).
Построение
Заполнить таблицу можно динамическим программированием. Базовый случай — отрезки длины 1: mn[0][i] = a[i]. Более длинный отрезок длины \(2^k\) разбивается на две половины длины \(2^{k-1}\):
\[ \text{mn}[k][i] = \min\bigl(\text{mn}[k-1][i],\ \text{mn}[k-1][i + 2^{k-1}]\bigr) \]
Каждая ячейка вычисляется за \(O(1)\), всего ячеек \(O(n \log n)\) — таково и время построения.
Запрос
Идея запроса основана на простом наблюдении:
любой полуинтервал \([l, r)\) можно покрыть двумя (возможно, пересекающимися) отрезками, длины которых — степени двойки.
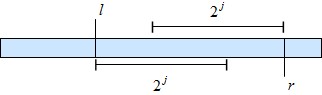
Возьмём \(k = \lfloor \log_2 (r - l) \rfloor\). Тогда два отрезка длины \(2^k\), упирающиеся в левый и правый концы запроса, целиком покроют \([l, r)\):
\[ \text{rmq}(l, r) = \min\bigl(\text{mn}[k][l],\ \text{mn}[k][r - 2^k]\bigr) \]
Чтобы запрос действительно работал за \(O(1)\), нужно уметь быстро вычислять \(\lfloor \log_2 x \rfloor\). В GCC для этого есть встроенная функция __lg: внутри она использует процессорную инструкцию clz («count leading zeros») и работает за несколько тактов.
Реализация
#include <vector>
#include <algorithm>
constexpr int LOGN = 20; // достаточно для n <= 10^6
std::vector<std::vector<int>> mn;
void Build(const std::vector<int>& a) {
int n = a.size();
mn.assign(LOGN, std::vector<int>(n));
mn[0] = a;
for (int k = 1; k < LOGN; ++k) {
for (int i = 0; i + (1 << k) <= n; ++i) {
mn[k][i] = std::min(mn[k - 1][i],
mn[k - 1][i + (1 << (k - 1))]);
}
}
}
int Rmq(int l, int r) { // полуинтервал [l, r)
int k = __lg(r - l);
return std::min(mn[k][l], mn[k][r - (1 << k)]);
}Ограничения на операцию
Разреженная таблица работает не только для минимума и максимума. От операции \(\circ\) требуются три свойства:
- ассоциативность: \(a \circ (b \circ c) = (a \circ b) \circ c\);
- коммутативность: \(a \circ b = b \circ a\);
- идемпотентность: \(a \circ a = a\).
Идемпотентность — самое жёсткое из этих условий и нужна именно для того, чтобы пересечение двух покрывающих отрезков «не мешало». Подходящие операции: минимум, максимум, \(\gcd\), побитовые AND и OR.
Если операция не идемпотентна (например, сумма), запрос всё ещё можно сделать, но уже не за \(O(1)\), а за \(O(\log n)\) — без перекрытия. Идея: каждый раз отрезаем от запроса самый длинный префикс длины степени двойки и переходим к остатку.
// sum[k][i] = сумма a[i..i + 2^k); строится так же, как mn
int Sum(int l, int r) { // [l, r)
int res = 0;
for (int k = LOGN - 1; k >= 0; --k) {
if (l + (1 << k) <= r) {
res += sum[k][l];
l += (1 << k);
}
}
return res;
}Получается \(O(\log n)\) слагаемых на запрос — асимптотически как у дерева отрезков, но с маленькой константой.
Применения
Разреженная таблица — статическая структура: построив её, мы не можем дёшево обновлять массив. Для динамических задач лучше подходит дерево отрезков.
Главное применение разреженной таблицы — задача LCA, к которой мы сейчас и переходим: её можно эффективно свести к static RMQ.
Наименьший общий предок (LCA)
Задача. Дано корневое дерево из \(n\) вершин. Поступают запросы вида «найти наименьшего общего предка вершин \(u\) и \(v\)» — то есть самую глубокую вершину \(w\), лежащую на пути от корня одновременно к \(u\) и к \(v\).
По-английски эта задача называется least common ancestor.
LCA возникает во многих задачах на деревьях: расстояние между двумя вершинами через корень, запросы на путях, обработка офлайн-запросов и так далее.
Простой алгоритм за \(O(n)\)
Запустим DFS из корня и для каждой вершины запомним время входа tin и время выхода tout. Тогда u — предок v тогда и только тогда, когда отрезок \([\text{tin}_u, \text{tout}_u]\) содержит отрезок \([\text{tin}_v, \text{tout}_v]\).
Чтобы найти LCA вершин \(u\) и \(v\), можно подниматься от \(u\) по предкам, пока она не станет предком \(v\):
bool IsAncestor(int u, int v) {
return tin[u] <= tin[v] && tout[v] <= tout[u];
}
int Lca(int u, int v) {
while (!IsAncestor(u, v)) {
u = parent[u];
}
return u;
}Время работы — \(O(h)\), где \(h\) — высота дерева. В худшем случае дерево — «бамбук», и один запрос отрабатывает за \(O(n)\).
Сведение к Static RMQ
Чтобы научиться отвечать на запросы быстрее, сведём LCA к RMQ.
Эйлеров обход
Запустим DFS из корня и будем выписывать вершины каждый раз, когда мы их посещаем — и при первом заходе, и при возвращении из ребёнка. Получится последовательность длины \(2n - 1\), которую называют эйлеровым обходом дерева.
Заведём также массив глубин: для каждой позиции эйлерова обхода — глубина соответствующей вершины.
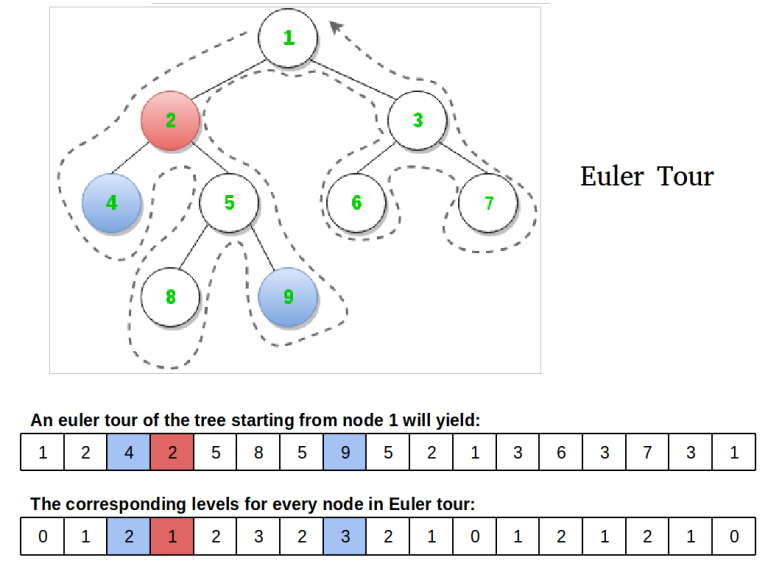
Дополнительно для каждой вершины \(v\) запомним first[v] — позицию её первого вхождения в эйлеров обход.
Алгоритм запроса
Пусть нужно найти LCA вершин \(u\) и \(v\). Без ограничения общности \(\text{first}[u] \le \text{first}[v]\). Рассмотрим часть эйлерова обхода между этими двумя позициями.
Утверждение. На этом отрезке обхода LCA — это вершина с наименьшей глубиной.
Действительно, единственный простой путь между \(u\) и \(v\) в дереве проходит через LCA. Двигаясь по эйлерову обходу от первого вхождения \(u\) к первому вхождению \(v\), мы как раз идём по этому пути: сначала поднимаемся до LCA, а затем спускаемся к \(v\). Выше LCA подняться нельзя, значит именно LCA — самая высокая (с минимальной глубиной) точка на этом отрезке.
Значит, чтобы найти LCA, достаточно:
- Взять отрезок \([\text{first}[u], \text{first}[v]]\) массива глубин.
- Найти на нём позицию минимума.
- Посмотреть, какая вершина стоит на этой позиции в эйлеровом обходе.
Шаг 2 — это уже знакомая нам задача RMQ на статическом массиве. Применив разреженную таблицу, получим ответ на каждый запрос LCA за \(O(1)\).
Сложность
| Этап | Время | Память |
|---|---|---|
| DFS + построение эйлерова обхода | \(O(n)\) | \(O(n)\) |
| Построение разреженной таблицы | \(O(n \log n)\) | \(O(n \log n)\) |
| Один запрос LCA | \(O(1)\) | — |
Это асимптотически оптимальный сложный алгоритм для LCA: лучше, чем сводить к RMQ через дерево отрезков (\(O(\log n)\) на запрос), и универсальнее, чем подъём по предкам (\(O(h)\) на запрос). Существуют и более изощрённые методы со сложностью препроцессинга \(O(n)\), но в большинстве задач разреженной таблицы достаточно.