Система непересекающихся множеств
Система непересекающихся множеств (англ. disjoint set union, DSU) — структура данных, которая хранит разбиение множества элементов на непересекающиеся подмножества и поддерживает две операции:
- Объединить два множества.
- Найти представителя (лидера) множества, в котором лежит заданный элемент.
Обе операции выполняются в среднем почти за \(O(1)\) (но не совсем — чуть позже разберёмся, что это значит).
Имея операцию «найти представителя», легко реализовать запрос «лежат ли элементы \(a\) и \(b\) в одном множестве»: достаточно сравнить представителей.
DSU часто используется в графовых алгоритмах для поддержки связности компонент — например, в алгоритме Краскала для построения минимального остова.
Устройство структуры
Множества элементов будем хранить в виде деревьев: одно множество — одно дерево. Корень дерева — это представитель (лидер) множества. Для корня считаем, что его родитель — он сам.
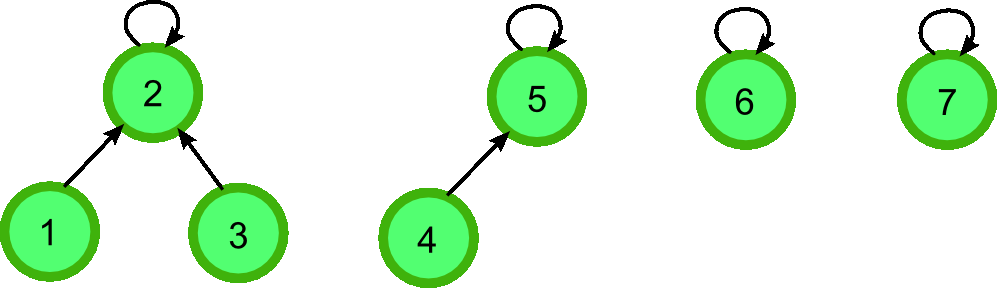
Заведём массив parent, в котором для каждого элемента храним номер его родителя в дереве. Изначально каждый элемент — сам себе родитель, то есть является отдельным множеством из одного элемента.
std::vector<int> parent;
void Init(int n) {
parent.resize(n);
for (int i = 0; i < n; ++i) {
parent[i] = i;
}
}Поиск лидера. Чтобы узнать, в каком множестве находится элемент \(v\), нужно подняться по ссылкам до корня:
int Leader(int v) {
if (parent[v] == v) {
return v;
}
return Leader(parent[v]);
}Объединение. Чтобы объединить множества элементов \(a\) и \(b\), нужно подвесить корень одного дерева за корень другого:
void Unite(int a, int b) {
a = Leader(a);
b = Leader(b);
if (a != b) {
parent[a] = b;
}
}К несчастью, в худшем случае такая реализация работает за \(O(n)\) на запрос. Действительно, последовательно присоединяя каждую новую вершину к уже полученному дереву, можно построить «бамбук» из \(n\) вершин — и последующие запросы Leader будут работать за линейное время.
Оптимизации
Разгонять наивную реализацию будем тремя независимыми эвристиками. Первая ускоряет поиск лидера, две другие — сам процесс объединения.
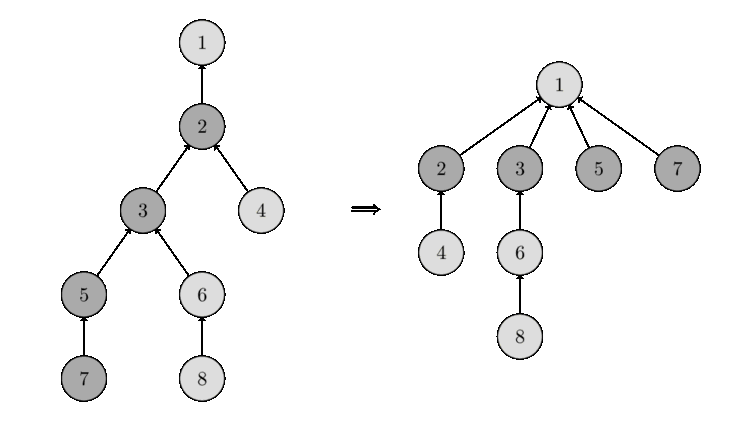
Сжатие пути
Когда мы вызвали Leader(v) и нашли корень, ничто не мешает нам сразу переподвесить \(v\) за этот корень. Тогда следующий вызов Leader(v) отработает за один шаг.
На самом деле можно переподвесить сразу все вершины на пути: достаточно дополнить рекурсивный вызов присваиванием.
int Leader(int v) {
if (parent[v] == v) {
return v;
}
parent[v] = Leader(parent[v]);
return parent[v];
}Эта оптимизация называется эвристикой сжатия пути (англ. path compression).
Ранговая и весовая эвристики
Следующие две эвристики идеологически похожи: обе стараются ограничить высоту дерева, выбирая правильный корень при объединении.
Ранговая эвристика. Для каждого корня будем хранить его ранг — высоту его поддерева. При объединении будем делать корнем более высокое дерево: это гарантирует, что высота дерева растёт как можно медленнее.
std::vector<int> rank_;
void Unite(int a, int b) {
a = Leader(a);
b = Leader(b);
if (a == b) return;
if (rank_[a] > rank_[b]) {
std::swap(a, b);
}
parent[a] = b;
if (rank_[a] == rank_[b]) {
++rank_[b];
}
}Весовая эвристика. Вместо высоты будем хранить размер поддерева и подвешивать меньшее дерево к большему.
std::vector<int> size_;
void Unite(int a, int b) {
a = Leader(a);
b = Leader(b);
if (a == b) return;
if (size_[a] > size_[b]) {
std::swap(a, b);
}
parent[a] = b;
size_[b] += size_[a];
}Эти две эвристики — ранговая и весовая — взаимоисключающие (одно дерево, один «вес»), но каждую из них можно свободно комбинировать со сжатием пути.
На практике чаще выбирают весовую эвристику — размеры компонент часто нужны в задачах сами по себе.
Реализация
Соберём финальную реализацию, использующую сжатие пути и весовую эвристику:
#include <vector>
std::vector<int> parent;
std::vector<int> size_;
void Init(int n) {
parent.resize(n);
size_.assign(n, 1);
for (int i = 0; i < n; ++i) {
parent[i] = i;
}
}
int Leader(int v) {
if (parent[v] == v) {
return v;
}
parent[v] = Leader(parent[v]);
return parent[v];
}
void Unite(int a, int b) {
a = Leader(a);
b = Leader(b);
if (a == b) return;
if (size_[a] > size_[b]) {
std::swap(a, b);
}
parent[a] = b;
size_[b] += size_[a];
}
bool SameSet(int a, int b) {
return Leader(a) == Leader(b);
}
int GetSize(int v) {
return size_[Leader(v)];
}Обратите внимание: корректное значение size_[v] имеет смысл только у корня. Поэтому GetSize сначала находит лидера.
Сложность операций
Асимптотика DSU зависит от того, какие эвристики мы применяем. Здесь и далее используется амортизированная оценка: мы оцениваем не худший случай для одной операции, а среднюю стоимость операции по всей последовательности запросов.
| Эвристики | Стоимость одной операции |
|---|---|
| Без оптимизаций | \(O(n)\) в худшем случае |
| Только сжатие пути | \(O(\log n)\) амортизированно |
| Только ранговая / весовая | \(O(\log n)\) в худшем случае |
| Сжатие пути + ранг/вес | \(O(\alpha(n))\) амортизированно |
Здесь \(\alpha(n)\) — обратная функция Аккермана. Она растёт настолько медленно, что для всех мыслимых значений \(n\) (в пределах вычислительных возможностей нашей Вселенной) не превосходит 4. Поэтому на практике считают, что DSU со всеми эвристиками работает за \(O(1)\) на операцию.
Чтобы показать эти оценки — отдельное упражнение:
- Для ранговой и весовой эвристики нетрудно доказать индукцией, что высота дерева из \(k\) вершин не превосходит \(\lfloor \log_2 k \rfloor\).
- Оценка \(O(\alpha(n))\) для комбинации эвристик — классический результат Тарьяна. Разобраться в доказательстве интересно, но не обязательно: для практических целей достаточно помнить, что это «почти \(O(1)\)».
Тратить время на чтение статьи на Википедии про функцию Аккермана автор не рекомендует.